Our aim is to develop a bio-nanomaterial system and a computational framework to construct an artificial perception system we call a Molecular Perceptron, for detecting a myriad of molecular species in a biofluid sample most notably blood, contain a plethora of molecules that together can accurately define the physiological state of a person. Sensing is a basic mechanism that is absolutely required for living. A bacterial cell is endowed by evolution with many types of sensors to inform the cell about its metabolic status and its environment. Man-made biosensors form the basis of diagnostics for modern medicine. In almost all these cases, a lock-and-key mechanism is employed for substrate recognition. This specific one-to-one recognition-based sensing is conceptually simple. And, it serves as the underlying principle for the design of most sensors in current technology.
However, there is a growing appreciation that this one-to-one recognition-based design is relatively primitive and may not be the most effective one from both computational and materials utilization point of view. We mammals perceive our environment in a very different way. We smell the presence of vinegar not through a vinegar specific receptor, but rather through an array of receptors with insignificant individual specificity. Rather, each receptor captures certain features of the target molecule and the overall ensemble response is then analyzed by the neural network in our brain resulting in perception. Even though each receptor element has little specificity towards any specific substrate, the whole receptor array nevertheless is under genetic control to ensure heritability and evolvability. As a matter of fact, 3% of the genes in the human genome encode the olfactory system. The transition from primitive one-to-one recognition-based sensing to perception is a decisive one that puts us at the top of the food chain. Conceptually we find that this mode of sensing has been generalized to non-molecule based sensing. Our visual perception, for example, our perception of color: we can differentiate hundreds of different colors by using only three photo-receptors that have broad and overlapping spectral responses. Our credo is that rather than attempting to accomplish this on a one-to-one recognition basis, it is far more effective to attempt it by Perception.
 Our long-term vision is to build a truly transformative sensing technology based on arrays of DNA-SWCNT sensing elements married to the molecular perceptron idea to offer scalability (for simultaneous measurement of 103 or more analyte molecules), evolvability (for continued improvement via DNA sequence and CNT selection), and targetability (for detection of specific biomarkers). The heart of this vision is the idea that spectral changes (shift and intensity changes of SWCNT spectral lines) of a judiciously selected collection of DNA-SWCNT can be connected to a detailed description of the metabolome via a trained machine learning algorithm. Our plan is to formulate and solve a few basic structure/function design problems, to demonstrate that the idea is scalable in terms of DNA-SWCNT receptor array construction and computational analysis of the array data. Specifically, we will solve the following two problems:
Our long-term vision is to build a truly transformative sensing technology based on arrays of DNA-SWCNT sensing elements married to the molecular perceptron idea to offer scalability (for simultaneous measurement of 103 or more analyte molecules), evolvability (for continued improvement via DNA sequence and CNT selection), and targetability (for detection of specific biomarkers). The heart of this vision is the idea that spectral changes (shift and intensity changes of SWCNT spectral lines) of a judiciously selected collection of DNA-SWCNT can be connected to a detailed description of the metabolome via a trained machine learning algorithm. Our plan is to formulate and solve a few basic structure/function design problems, to demonstrate that the idea is scalable in terms of DNA-SWCNT receptor array construction and computational analysis of the array data. Specifically, we will solve the following two problems:
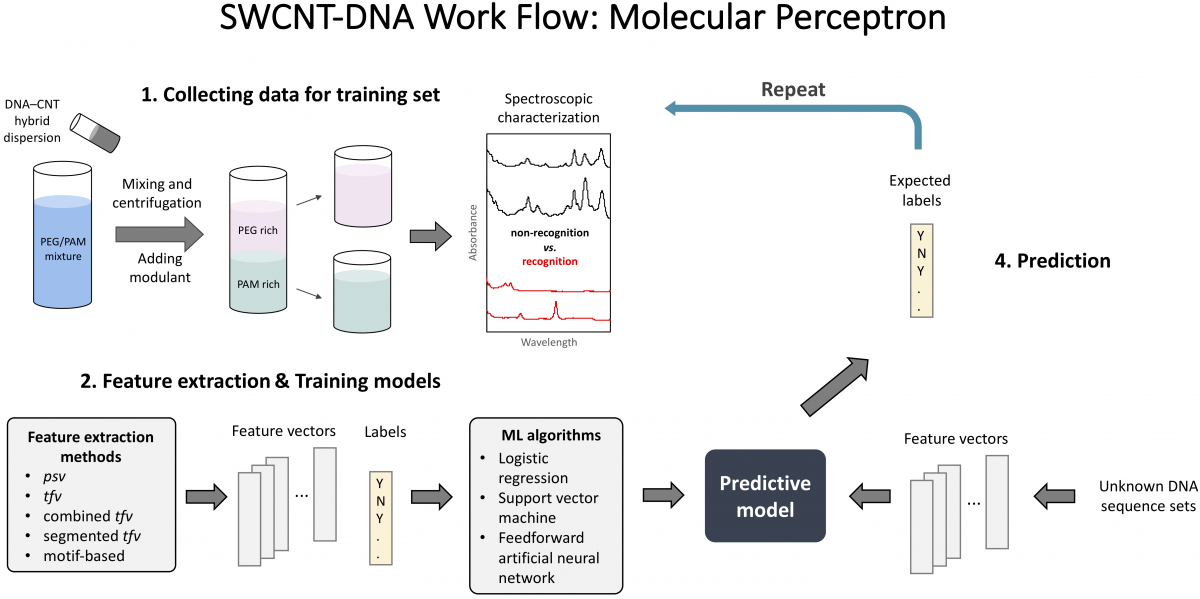
1. Collecting data for the training set: selection of the > 100 special DNA sequences for the construction of the DNA-SWCNT receptor arrays (Molecular Perceptron). This will be accomplished via the combined experimental and machine learning/coarse grained MD based method. Assuming a synthetic SWCNT mixture has > 10 different semiconducting species, we will be able to construct a receptor array with 1000 elements. The figure shows how a technique called aqueous two-phase (ATP) separation can be used to separate individual SWCNT chiralities (sometimes by handedness) characterized by optical spectroscopy. An ATP system consists of a solvent (water) into which two water-soluble polymers (polyethylene glycol (PEG)/Dextran (DX)) are dissolved. The system separates into two phases with slightly different solvation free energy for a solute, in our case DNA/SWCNT. A final player is a modulant molecule polyvinylpyrrolidone (PVP) that, by tuning the solvation free energy difference can change how the solute partitions between the two phases. The DNA sequences that can specifically sort SWCNT chiralities are labeled as “Y” for yes and “N” for no.
2. Feature extraction and training models: We apply machine learning methods to accelerate the discovery of special DNA sequences by training on existing experimental sequence data sets. Multiple input feature construction methods (position-specific, term-frequency, combined or segmented term frequency vector, and motif-based feature) are used and compared. The transformed features are used to train several classifier algorithms (logistic regression, support vector machine and artificial neural network). Trained models are used to predict new sets of recognition sequences, and consensus among a number of models is used successfully to counteract the limited size of the data set. Predictions are tested using aqueous two-phase separation. New data thus acquired is used to retrain the models by adding an experimentally tested new set of predicted sequences to the original set. Thus the trained model can be used to rapidly generate candidate sequences from the vast DNA library with a much greater chance of success. Development and training of the Molecular Perceptron effort to resolve the entire metabolome of a biofluid is a loop combining experimental and computational work.